Handwritten Text Recognition of the Dunhuang manuscripts: the challenges of machine learning on ancient Chinese texts
This blog post is by Peter Smith, DPhil Student at the Faculty of Asian and Middle Eastern Studies, University of Oxford.
Introduction
The study of writing and literature has been transformed by the mass transcription of printed materials, aided significantly by the use of Optical Character Recognition (OCR). This has enabled textual analysis through a growing array of digital techniques, ranging from simple word searches in a text to linguistic analysis of large corpora – the possibilities are yet to be fully explored. However, printed materials are only one expression of the written word and tend to be more representative of certain types of writing. These may be shaped by efforts to standardise spelling or character variants, they may use more formal or literary styles of language, and they are often edited and polished with great care. They will never reveal the great, messy diversity of features that occur in writings produced by the human hand. What of the personal letters and documents, poems and essays scribbled on paper with no intention of distribution; the unpublished drafts of a major literary work; or manuscript editions of various classics that, before the use of print, were the sole means of preserving ancient writings and handing them onto future generations? These are also a rich resource for exploring past lives and events or expressions of literary culture.
The study of handwritten materials is not new but, until recently, the possibilities for analysing them using digital tools have been quite limited. With the advent of Handwritten Text Recognition (HTR) the picture is starting to change. HTR applications such as Transkribus and eScriptorium are capable of learning to transcribe a broad range of scripts in multiple languages. As the potential of these platforms develops, large collections of manuscripts can be automatically transcribed and consequently explored using digital tools. Institutions such as the British Library are doing much to encourage this process and improve accessibility of the transcribed works for academic research and the general interest of the public. My recent role in an HTR project at the Library represents one small step in this process and here I hope to provide a glimpse behind-the-scenes, a look at some of the challenges of developing HTR.
As a PhD student exploring classical Chinese texts, I was delighted to find a placement at the British Library working on HTR of historical Chinese manuscripts. This project proceeded under the guidance of my British Library supervisors Dr Adi Keinan-Schoonbaert and Mélodie Doumy. I was also provided with support and expertise from outside of the Library: Colin Brisson is part of a group working on Chinese Historical documents Automatic Transcription (CHAT). They have already gathered and developed preliminary models for processing handwritten Chinese with the open source HTR application eScriptorium. I worked with Colin to train the software further using materials from the British Library. These were drawn entirely from the fabulous collection of manuscripts from Dunhuang, China, which date back to the Tang dynasty (618–907 CE) and beyond. Examples of these can be seen below, along with reference numbers for each item, and the originals can be viewed on the new website of the International Dunhuang Programme. Some of these texts were written with great care in standard Chinese scripts and are very well preserved. Others are much more messy: cursive scripts, irregular layouts, character corrections, and margin notes are all common features of handwritten work. The writing materials themselves may be stained, torn, or eaten by animals, resulting in missing or illegible text. All these issues have the potential to mislead the ‘intelligence’ of a machine. To overcome such challenges the software requires data – multiple examples of the diverse elements it might encounter and instruction as to how they should be understood.
The challenges encountered in my work on HTR can be examined in three broad categories, reflecting three steps in the HTR process of eScriptorium: image binarisation, layout segmentation, and text recognition.
Image binarisation
The first task in processing an image is to reduce its complexity, to remove any information that is not relevant to the output required. One way of doing this is image binarisation, taking a colour image and using an algorithm to strip it of hue and brightness values so that only black and white pixels remain. This was achieved using a binarisation model developed by Colin Brisson and his partners. My role in this stage was to observe the results of the process and identify strengths and weaknesses in the current model. These break down into three different categories: capturing details, stained or discoloured paper, and colour and density of ink.
1. Capturing details
In the process of distinguishing the brushstrokes of characters from other random marks on the paper, it is perhaps inevitable that some thin or faint lines – occurring as a feature of the hand written text or through deterioration over time – might be lost during binarisation. Typically the binarisation model does very well in picking them out, as seen in figure 1:

While problems with faint strokes are understandable, it was surprising to find that loss of detail was also an issue in somewhat thicker lines. I wasn’t able to determine the cause of this but it occurred in more than one image. See figures 2 and 3:


2. Stained and discoloured paper
Where paper has darkened over time, the contrast between ink and background is diminished and during binarisation some writing may be entirely removed along with the dark colours of the paper. Although I encountered this occasionally, unless the background was really dark the binarisation model did well. One notable success is its ability to remove the dark colours of partially stained sections. This can be seen in figure 4, where a dark stain is removed while a good amount of detail is retained in the written characters.

3. Colour and density of ink
The majority of manuscripts are written in black ink, ideal for creating good contrast with most background colourations. In some places however, text may be written with less concentrated ink, resulting in greyer tones that are not so easy to distinguish from the paper. The binarisation model can identify these correctly but sometimes it fails to distinguish them from the other random markings and colour variations that can be found in the paper of ancient manuscripts. Of particular interest is the use of red ink, which is often indicative of later annotations in the margins or between lines, or used for the addition of punctuation. The current binarisation model will sometimes ignore red ink if it is very faint but in most cases it identifies it very well. In one impressive example, shown in figure 5, it identified the red text while removing larger red marks used to highlight other characters written in black ink, demonstrating an ability to distinguish between semantic and less significant information.

In summary, the examples above show that the current binarisation model is already very effective at eliminating unwanted background colours and stains while preserving most of the important character detail. Its response to red ink illustrates a capacity for nuanced analysis. It does not treat every red pixel in the same way, but determines whether to keep it or remove it according to the context. There is clearly room for further training and refinement of the model but it already produces materials that are quite suitable for the next stages of the HTR process.
Layout segmentation
Segmentation defines the different regions of a digitised manuscript and the type of content they contain, either text or image. Lines are drawn around blocks of text to establish a text region and for many manuscripts there is just one per image. Anything outside of the marked regions will just be ignored by the software. On occasion, additional regions might be used to distinguish writings in the margins of the manuscript. Finally, within each text region the lines of text must also be clearly marked. Having established the location of the lines, they can be assigned a particular type. In this project the options include ‘default’, ‘double line’, and ‘other’ – the purpose of these will be explored below.
All of this work can be automated in eScriptorium using a segmentation model. However, when it comes to analysing Chinese manuscripts, this model was the least developed component in the eScriptorium HTR process and much of our work focused on developing its capabilities. My task was to run binarised images through the model and then manually correct any errors. Figure 6 shows the eScriptorium interface and the initial results produced by the segmentation model. Vertical sections of text are marked with a purple line and the endings of each section are indicated with a horizontal pink line.
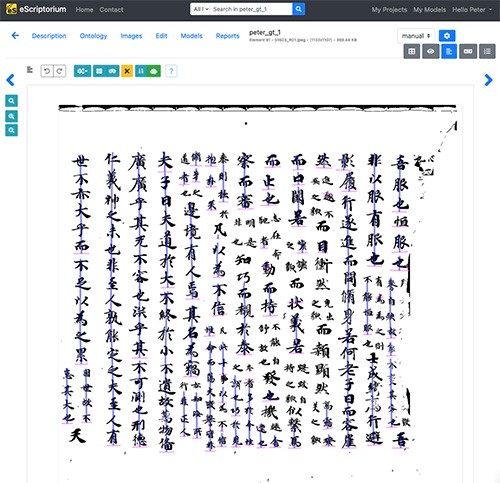
This example shows that the segmentation model is very good at positioning a line in the centre of a vertical column of text. Frequently, however, single lines of text are marked as a sequence of separate lines while other lines of text are completely ignored. The correct output, achieved through manual segmentation, is shown in figure 7. Every line is marked from beginning to end with no omissions or inappropriate breaks.

Once the lines of a text are marked, line masks can be generated automatically, defining the area of text around each line. Masks are needed to show the transcription model (discussed below) exactly where it should look when attempting to match images on the page to digital characters. The example in figure 8 shows that the results of the masking process are almost perfect, encompassing every Chinese character without overlapping other lines.

The main challenge with developing a good segmentation model is that manuscripts in the Dunhuang collection have so much variation in layout. Large and small characters mix together in different ways and the distribution of lines and characters can vary considerably. When selecting material for this project I picked a range of standard layouts. This provided some degree of variation but also contained enough repetition for the training to be effective. For example, the manuscript shown above in figures 6–8 combines a classical text written in large characters interspersed with double lines of commentary in smaller writing, in this case it is the Zhuangzi Commentary by Guo Xiang. The large text is assigned the ‘default’ line type while the smaller lines of commentary are marked as ‘double-line’ text. There is also an ‘other’ line type which can be applied to anything that isn’t part of the main text – margin notes are one example. Line types do not affect how characters are transcribed but they can be used to determine how different sections of text relate to each other and how they are assembled and formatted in the final output files.

Figures 8 and 9, above, represent standard layouts used in the writing of a text but manuscripts contain many elements that are more random. Of these, inter-line annotations are a good example. They are typically added by a later hand, offering comments on a particular character or line of text. Annotations might be as short as a single character (figure 10) or could be a much longer comment squeezed in between the lines of text (figure 11). In such cases these additions can be distinguished from the main text by being labelled with the ‘other’ line type.


Other occasional features include corrections to the text. These might be made by the original scribe or by a later hand. In such cases one character may be blotted out and a replacement added to the side, as seen in figure 12. For the reader, these should be understood as part of the text itself but for the segmentation model they appear similar or identical to annotations. For the purpose of segmentation training any irregular features like this are identified using the ‘other’ line type.

As the examples above show, segmentation presents many challenges. Even the standard features of common layouts offer a degree of variation and in some manuscripts irregularities abound. However, work done on this project has now been used for further training of the segmentation model and reports are promising. The model appears capable of learning quickly, even from relatively small data sets. As the process improves, time spent using and training the model offers increasing returns. Even if some errors remain, manual correction is always possible and segmented images can pass through to the final stage of text recognition.
Text recognition
Although transcription is the ultimate aim of this process it consumed less of my time on the project so I will keep this section relatively brief. Fortunately, this is another stage where the available model works very well. It had previously been trained on other print and manuscript collections so a well-established vocabulary set was in place, capable of recognising many of the characters found in historical writings. Dealing with handwritten text is inevitably a greater challenge for a transcription model but my selection of manuscripts included several carefully written texts. I felt there was a good chance of success and was very keen to give it a go, hoping I might end up with some usable transcriptions of these works. Once the transcription model had been run I inspected the first page using eScriptorium’s correction interface as illustrated in figure 13.

The interface presents a single line from the scanned image alongside the digitally transcribed text, allowing me to check each character and amend any errors. I quickly scanned the first few lines hoping I would find something other than random symbols – I was not disappointed! The results weren’t perfect of course but one or two lines actually came through with no errors at all and generally the character error rate seems very low. After careful correction of the errors that remained and some additional work on the reading order of the lines, I was able to export one complete manuscript transcription bringing the whole process to a satisfying conclusion.
Final thoughts
Naturally there is still some work to be done. All the models would benefit from further refinement and the segmentation model in particular will require training on a broader range of layouts before it can handle the great diversity of the Dunhuang collection. Hopefully future projects will allow more of these manuscripts to be used in the training of eScriptorium so that a robust HTR process can be established. I look forward to further developments and, for now, am very grateful for the chance I’ve had to work alongside my fabulous colleagues at the British Library and play some small role in this work.
This article was originally posted on Digital Scholarship Blog on 18 March 2024.






If you have feedback or ideas about this post, contact us, sign in or register an account to leave a comment below